|
| Download Postscript File | Download Compressed Postscript File |
Eugenia Kalnay1,2,3,![[*]](../gif/foot_motif.gif) , Seon Ki Park2, Zhao-Xia Pu1 and Jidong Gao4
, Seon Ki Park2, Zhao-Xia Pu1 and Jidong Gao4
1National Centers for Environmental Prediction
NWS/NOAA, Washington, D.C. 20233
2Cooperative Institute for Mesoscale Meteorological Studies
3School of Meteorology
4Center for Analysis and Prediction of Storms
University of Oklahoma, Norman, OK 73019
December 1998 (Revised)
Submitted to Monthly Weather Review.
ABSTRACT
|
Four-dimensional variational data assimilation (4D-Var) seeks to
find an optimal initial field that minimizes a cost function
defined as the squared distance between model solutions and
observations within an assimilation window. For a perfect linear
model, Lorenc showed that the 4D-Var forecast at the end of the
window coincides with a Kalman Filter analysis if two conditions
are fulfilled: a) the addition to the cost function of a term that
measures the distance to the background at the beginning of the
assimilation window, and b) the use of the Kalman Filter
background error covariance in this term. The standard 4D-Var
requires minimization algorithms along with adjoint models to
compute gradient information needed for the minimization. In this
study, we suggest that an alternative method based on the use of
the quasi-inverse model that, for certain applications, may help
accelerate the solution of problems close to 4D-Var.
We introduce the quasi-inverse approach for the forecast sensitivity problem, and then formulate a closely related variational assimilation problem using the quasi-inverse model (i.e., the model integrated backwards but changing the sign of the dissipation terms). We show that if the cost function has no background term, and has a complete set of observations (as assumed in many classical 4D-Var papers), the new method solves the 4D-Var-minimization problem efficiently, and is in fact equivalent to the Newton algorithm but without having to compute a Hessian. If the background term is included but computed at the end of the interval, allowing the use of observations that are not complete, the minimization can still be carried out very efficiently. In this case, however, the method is much closer to a 3D-Var formulation in which the analysis is attained through a model integration. For this reason, we call the method ``Inverse 3D-Var'' (I3D-Var). We applied the I3D-Var method to simple models (Burgers' equation and Lorenz model), and found that when the background term is ignored and complete fields of noisy observations are available at multiple times, the Inverse 3D-Var method minimizes the same cost function as 4D-Var but converges much faster. Tests with the Advanced Regional Prediction System (ARPS), indicate that I3D-Var is about twice as fast as the Adjoint Newton Method and many times faster than the quasi-Newton LBFGS algorithm, which uses the adjoint model. Potential problems (including the growth of random errors during the integration back in time) and possible applications to problems such as storm-scale data assimilation and reanalysis are also discussed. |
1. Introduction
Over the last decade many important applications of the backward integration of the adjoint of the linear tangent model have been introduced in the literature. These include the generation of singular vectors for ensemble prediction (e.g., Molteni et al. 1996); four-dimensional variational data assimilation (e.g., Lewis and Derber 1985; Le Dimet and Talagrand 1986; Courtier et al. 1994); forecast sensitivity to the initial conditions (Rabier et al. 1996; Pu et al. 1997a); and targeted observations (e.g., Rohaly et al. 1998; Pu et al. 1998).
Among advanced methods for data assimilation, 4-dimensional Variational data assimilation (4D-Var) is the approach that has received the most attention in recent years (Derber 1989; Courtier et al. 1994; M. Zupanski 1993; and many other papers). A simplified version has been implemented recently at ECMWF (Bouttier and Rabier 1997; Rabier et al. 1997), and at the time of this writing, NCEP is testing a 4D-Var system for the Eta model.
In 4D-Var a cost function is defined as the squared distance between a model integration and the observations in a given assimilation interval. Lorenc (1986, 1988) showed that for a linear perfect model, if a) a background error term is added to the cost function at the beginning of the assimilation period, and b) the background error covariance is the same as that used in the Kalman Filter (KF) at the initial time, then the 4D-Var analysis at the end of the interval is the same that would be obtained using the KF. This makes 4D-Var attractive, because it is much less expensive than KF (see also Daley 1991, and Thepaut et al. 1993).
4D-Var provides initial conditions for a model integration that is close to the observations, but it also has some disadvantages: a) It is difficult to include forecast error covariances in the cost function except at the beginning of the interval, which forces the use of short assimilation intervals in order to maintain the impact of model errors small. It is obvious from Lorenz chaos theory that even with a perfect model, one would not want to perform 4D-Var over, for example, a two-week data assimilation interval, since the 4D-Var analysis would be given by the state of the model after a two-week integration, when the predictability has been lost (Pires et al. 1996). Even if the assimilation interval is reduced to a shorter period, such as 6-24 hours, the neglect of model errors during the forecast can lead to unrealistic results (Menard and Daley 1996). There have been attempts to include simple evolving model errors (e.g., Derber 1989; D. Zupanski 1997) but much remains to be done in this area. b) 4D-Var has a large computational cost compared to 3D-Var (typically 10-100 or more iterations are required for convergence, equivalent to about 30-300 model integrations per day). ECMWF, for example, has a powerful supercomputer about 25 times faster than a Cray C90, and has been running a model at a horizontal resolution of T213. Nevertheless, ECMWF had to make several simplifying assumptions in their implementation of 4D-Var (such as using a lower horizontal resolution model of T63 and a short assimilation window) in order to reduce the computational cost (Bouttier and Rabier 1997; Rabier et al. 1997).
Recently Wang et al. (1997) suggested the use of backward model integrations in order to accelerate the convergence of 4D-Var (without including background error in the cost function). Pu et al. (1997a) showed that for the problem of forecast sensitivity, closely related to 4D-Var, a backward integration with the ``quasi-inverse'' of the tangent linear model (TLM) gave results far superior to those obtained using the adjoint model. The quasi-inverse model is simply the model integrated backwards but changing the sign of dissipative terms in order to avoid computational blow-up. It can be applied to either the tangent linear or the full nonlinear model, each of which has advantages for different applications. The quasi-inverse linear (QIL) method has been tested successfully at NCEP in several different applications, e.g., forecast error sensitivity analysis and data assimilation (Pu et al. 1997a), and adaptive observations (Pu et al. 1998).
Wang et al. (1997) adopted the quasi-inverse approach for their adjoint Newton algorithm (ANA), and applied it to a simplified 4D-Var problem, using simulated data, using the Advanced Regional Prediction System (ARPS; Xue et al. 1995), with impressive results. They assumed the availability of a complete set of observations at the end of the assimilation interval, and showed that the ANA converged in an order of magnitude fewer iterations, and to an error level an order of magnitude smaller than the conventional adjoint approach to solve the same (simplified) 4D-Var problem.
Kalnay and Pu (1998) generalized Wang et al. (1997) approach by including a background term to the cost function and further simplified the method. The background error term in the cost function allows using incomplete sets of observations, but in order to maintain the efficiency of the method, it is necessary to estimate the background error term at the end of the assimilation interval, rather than at the beginning as in Lorenc (1986) formulation. We have further generalized the method to allow for the assimilation of data at different times, rather than only at the end of the interval, as in Wang et al. (1997). The results suggest that the quasi-inverse model may be used in data assimilation for accelerating convergence and reducing spin-up problems, although problems may arise when tested on comprehensive atmospheric models.
In this paper we first introduce the quasi-inverse approach for the forecast sensitivity problem, and then formulate a closely related variational assimilation problem using the quasi-inverse model (section 2). We show that if the cost function has no background term, and has a complete set of observations (as was assumed in many classical 4D-Var papers), the new method solves the 4D-Var-minimization problem efficiently, and is in fact equivalent to the Newton algorithm but without having to compute a Hessian. If the background term is included but computed at the end of the interval, the minimization can still be carried out very efficiently, but in this case it the method is closer to a 3D-Var formulation in which the analysis is attained through a model integration. For this reason, we call the method ``Inverse 3D-Var'' (I3D-Var).
In section 3 we introduce a simple ``model'' (viscous Burger's equation with advection of a passive scalar) which includes effects mimicking the three main components of atmospheric models: advection, large-scale instabilities, and dissipative processes. Using this simple model we show the effects of applying a linear tangent model, its adjoint, the exact inverse, and the quasi-inverse model, and compare one iteration of Inverse 3D-Var and adjoint 4D-Var. In section 4 we present preliminary results comparing Inverse 3D-Var and the adjoint 4D-Var using Burger's model and Lorenz's model (Lorenz 1963). We show that when the background term is ignored and complete fields of noisy observations are available at multiple times, the Inverse 3D-Var method still minimizes the same cost function as 4D-Var (but much more efficiently). Section 5 discusses several topics related to possible applications of Inverse 3D-Var: assimilation of data at multiple time levels, research on a storm-scale model with reversible clouds for storm-forecast initialization, and the problem of random observational errors which may amplify during the backward integration (Reynolds and Palmer 1998).
2. Formulation of Inverse 3D-Var
a. Forecast sensitivity
We introduce Inverse 3D-Var by first considering the forecast
sensitivity problem posed by Rabier et al (1996): Find the change
in initial conditions ![]() that ``optimally'' corrects a
perceived forecast error at the final time t. In what follows,
Mt is a nonlinear forecast operator that advances the model
state x from t = 0 to the final time t, i.e., xt = Mt
(x0). A is the analysis, E = At - Mt (x0) is the
perceived error, L is the linear propagator (linear tangent
model integrated forward in time), and LT is its adjoint.
Then
that ``optimally'' corrects a
perceived forecast error at the final time t. In what follows,
Mt is a nonlinear forecast operator that advances the model
state x from t = 0 to the final time t, i.e., xt = Mt
(x0). A is the analysis, E = At - Mt (x0) is the
perceived error, L is the linear propagator (linear tangent
model integrated forward in time), and LT is its adjoint.
Then ![]() is the solution of
is the solution of
| (1) |
| (2) |
1) ADJOINT APPROACH (RABIER ET AL. 1996; PU ET AL. 1997B):
In the standard adjoint approach, we define a cost function using,
for example, an energy norm (i.e., the energy of a vector y defined as
(Wy)T(Wy) = yTW2y with W a weight matrix):
| (3) |
| (4) |
Equation (4) indicates that to obtain the gradient of the cost function we have to integrate backwards with the adjoint model, starting from the perceived error at the final time. This gives the ``optimal'' direction that results in the maximum decrease of the cost function for a given size perturbation. The adjoint procedure requires in addition an estimation of an appropriate amplitude ![]() , after which the adjoint sensitivity correction becomes
, after which the adjoint sensitivity correction becomes
| (5) |
2) QUASI-INVERSE APPROACH:
In the Quasi-Inverse Linear (QIL) approach we try to solve (2)
directly, but in order to do so, we need to have an approximation
of the inverse of the TLM:
| (6) |
The QIL approximation to L-1 consists of simply running the
TLM backward (changing the sign of ![]() , and also changing
the sign of the dissipative terms to avoid computational blow-up).
Pu et al. (1997a) found that this is a rather accurate
approximation to the inverse model. It solves a deterministic
problem, so that there is no need to find an optimal amplitude, as
required by the adjoint method. Reynolds and Palmer (1998)
compared this method with running the exact inverse (using a
Runge-Kutta time scheme and no change in sign for dissipation).
They found that the presence of dissipation during the backward
integration had a beneficial effect of a small reduction in
noisiness.
, and also changing
the sign of the dissipative terms to avoid computational blow-up).
Pu et al. (1997a) found that this is a rather accurate
approximation to the inverse model. It solves a deterministic
problem, so that there is no need to find an optimal amplitude, as
required by the adjoint method. Reynolds and Palmer (1998)
compared this method with running the exact inverse (using a
Runge-Kutta time scheme and no change in sign for dissipation).
They found that the presence of dissipation during the backward
integration had a beneficial effect of a small reduction in
noisiness.
Note that the inverse solution is not ``optimal'' like the adjoint
solution, since there is no constraint on the size of ![]() .
However, the inverse approach can be considered to be ``perfect'':
it reaches in a single step the same solution (
.
However, the inverse approach can be considered to be ``perfect'':
it reaches in a single step the same solution (![]() 0)
that the adjoint approach would reach after many iterations. It
should be pointed out that Lorenc (1988) integrated the NMC nested
grid model (NGM) backward with a change of sign in the physics,
but in his experiments he was attempting to approximate the
adjoint model, not the inverse model.
0)
that the adjoint approach would reach after many iterations. It
should be pointed out that Lorenc (1988) integrated the NMC nested
grid model (NGM) backward with a change of sign in the physics,
but in his experiments he was attempting to approximate the
adjoint model, not the inverse model.
b. Inverse 3D-Var
Wang et al. (1997) were trying to solve the 4D-Var problem on what they denote the ``estimated Newton descent direction'' rather than the descent direction provided by the standard adjoint approach. For this purpose they needed to approximate the inverse TLM, and succeeded by adopting the QIL method. In the experiments they did with simulated data and the adiabatic version of the ARPS model, they got convergence in an order of magnitude fewer iterations with the new method (ANA), and a decrease of the cost function which was also an order of magnitude better than with the adjoint approach. They assimilated simulated data only at the end of the interval, and only the full model field, so that they did not need a background error term in the cost function.
In this subsection we generalize their approach by including both data and background distance in the cost function, with appropriate error covariances. In order to maintain the ability to solve the minimization efficiently, however, the background term is estimated at the end of the interval, rather than at the beginning as in Lorenc (1986). Our derivation is also considerably simpler than the ANA method, and our method does not require line minimization, as in Wang et al (1997). As a result, our method is about twice as fast as the ANA approach.
Assume (for the moment) that data yo is available at the end
of the assimilation interval t, with ![]() =xa-xb,
=xa-xb,
![]() =yo-
=yo-![]() (xb). Here xa and xb
are the analysis and first guess, respectively, and
(xb). Here xa and xb
are the analysis and first guess, respectively, and ![]() is the ``forward observation operator'' which converts the model
first guess into first guess observations (Ide et al. 1997). The
cost function that we minimize is the 3D-Var cost function at the
end of the interval. It is given by the distance to the background
of the forecast at the end of the time interval (weighted by the
inverse of the forecast error covariance B), plus the distance to
the observations (weighted by the inverse of the observational
error covariance R), also at the end of the interval:
is the ``forward observation operator'' which converts the model
first guess into first guess observations (Ide et al. 1997). The
cost function that we minimize is the 3D-Var cost function at the
end of the interval. It is given by the distance to the background
of the forecast at the end of the time interval (weighted by the
inverse of the forecast error covariance B), plus the distance to
the observations (weighted by the inverse of the observational
error covariance R), also at the end of the interval:
| (7) |
| (8) |
From this equation we see that the gradient of the cost function is given by the backward adjoint integration of the rhs terms in (8). In the adjoint 4D-Var, an iterative algorithm (such as quasi-Newton, conjugate gradient, or steepest descent) is used to estimate an optimum perturbation:
| (9) |
In the Inverse 3D-Var, however, we seek to obtain directly the ``perfect solution'' i.e., the ![]() that makes
that makes ![]() =0 for small
=0 for small ![]() . From (8) we can eliminate the adjoint operator, and obtain the ``perfect'' solution given by
. From (8) we can eliminate the adjoint operator, and obtain the ``perfect'' solution given by
| (10) |
| (11) |
This can be interpreted as starting from the 3D-Var analysis increment at the end of the interval and integrating backwards with the TLM or an approximation of it. If we do not include the forecast error covariance term B-1, (11) reduces to the ANA algorithm of Wang et al (1997) except that we do not require line minimization. We have tested the Inverse 3D-VAR with the ARPS model and found that for this reason, the Inverse 3D-Var is computationally about twice as fast as Wang et al (1997) ANA scheme.
c. Equivalence of Inverse 3D-Var and the Newton minimization algorithm
It is easy to prove that the Inverse 3D-Var approach is equivalent to solving the minimization problem (at each time level) using the ideal Newton iterative method (e.g., Gill et al. 1981). Suppose that we are seeking the minimum of a cost function at x+![]() , and our present estimate of the solution is x. Then by Taylor expansion,
, and our present estimate of the solution is x. Then by Taylor expansion,
| (12) |
| (13) |
For the specific cost function (7), the Hessian is given by
| (14) |
| (15) |
The Inverse 3D-Var algorithm solves exactly the same problem but
takes advantage of the fact that the lhs of (12)
![]() (x+
(x+![]() ) = 0 can be solved directly (cf. Eqs. 8 and
11). Therefore the Inverse 3D-Var iteration (11) is identical to
the Newton algorithm iteration (15), but it is not necessary to
compute the Hessian or the gradient, just to integrate the linear
tangent model backwards.
) = 0 can be solved directly (cf. Eqs. 8 and
11). Therefore the Inverse 3D-Var iteration (11) is identical to
the Newton algorithm iteration (15), but it is not necessary to
compute the Hessian or the gradient, just to integrate the linear
tangent model backwards.
The results of Wang et al. (1997) and Pu et al. (1997b) support considerable optimism for this method. For a quadratic function, the Newton algorithm (and the equivalent Inverse 3D-Var) converges in a single iteration. Since the cost functions used in 4D-Var are close to quadratic functions, Inverse 3D-Var can be considered equivalent to perfect preconditioning of the simplified 4D-Var problem.
d. Multiple time levels of data
If there are data at different time levels we can choose to bring the data increments to the same initial time level (as shown schematically in Fig. 1) so that the increments corresponding to the different data can be averaged, with weights that may depend on the time level or the type of data. For applications in which ``knowing the future'' is allowed, such as reanalysis, the observational increments could be brought to the center of an interval, and used for the final analysis. In section 4 we show that, in a simple nonlinear model with complete data, when increments are brought to the same initial time, we solve a separate minimization for each time level, but that in fact (at least for this model) the I3D-Var minimizes the same multiple-level cost function as the simplified 4D-Var problem.

3. Burgers' equation example
a. Simple TLM, adjoint and inverse model formulation
Consider the simplest example of a model with advection of a passive scalar and diffusion, based on Burgers' equation
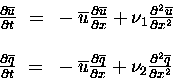 |
(16) |
![]()
The linear perturbation model is then
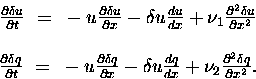 |
(17) |
![]()
![]()
| (18) |
Assume
![]()
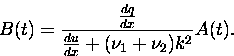 |
(19) |
| (20) |
final perturbation = (large scale advection)(large scale instability)(diffusion)initial perturbation.The equation for
The Tangent Linear Model (TLM) or propagator between time=0 and time=t, is then
| (21) |
| (22) |
| (23) |
| (24) |
If we integrate forward with the linear model followed by a backward integration with the exact inverse we get the exact initial conditions:
| L-1L = I. | (25) |
| (26) |
| (27) |
b. Application of 4D-Var and Inverse 3D-Var to Burgers' equation
Let us assume that ![]() (observations are made in the
model variable space), and neglect for the moment diffusion terms.
Then
(observations are made in the
model variable space), and neglect for the moment diffusion terms.
Then
![]()
![\begin{displaymath}
B~=~\frac{1}{\alpha} \left[ \begin{array}
{cc}
1 & 0 \\
...
...cc}
1 & 0 \\
0 & \frac{Q^{2}}{U^{2}}
\end{array} \right],
\end{displaymath}](img55.gif) |
(28) |
Then, from (10), the Inverse 3D-Var analysis is given by
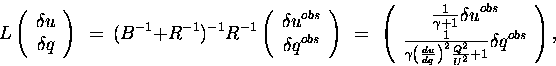 |
(29) |
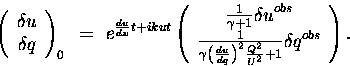 |
(30) |
The first iteration of the regular 4D-Var, on the other hand, is:
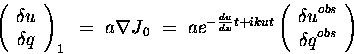 |
(31) |
4. Numerical experiments
We have performed preliminary experiments with the NCEP global model (Pu et al. 1997a), and with two simple models, the Lorenz (1963) model and Burgers' equation with passive transport.
a. The NCEP global model
The application to the global NCEP model was a forecast sensitivity approach. The 24 hour forecast error was estimated from the 24-hour analysis, and the difference between the analysis and the forecast was integrated backwards, using the TLM of the NCEP global model, with the sign of surface friction and horizontal diffusion changed. The results were very encouraging, indicating that the correction of the forecast was considerably better than using the adjoint sensitivity approach, even when the latter was iterated 5 times (Pu et al. 1997a). Several important points should be noted:
b. Burgers' equation with advection of a passive scalar
We performed some numerical tests with Burgers' equation including advection of a passive scalar (16). It should be noted that the model had been originally programmed using the Lax scheme (e.g., Anderson et al. 1984), which is highly diffusive and far from reversible (S. K. Park, personal communication, 1998). Such a scheme would not be appropriate for a method that requires approximating the inverse of the model by running it backwards. This was easily solved by rewriting the model with a leapfrog scheme for advection (with a forward first time step) and DuFort-Frankel for diffusion (e.g., Anderson et al. 1984). Therefore the numerical scheme was fully reversible except for the first forward time step. This allowed us to compare the effects of using the exact inverse linear model (IL) and the quasi-inverse linear model (QIL) as long as the Reynolds number was large enough (i.e., low dissipation) for the exact inverse to remain computationally stable.
The results were excellent. Fig. 2a shows the cost function for a case in which the first guess included errors of 50 %, and the observations were exact. As in Wang et al. (1997), the observation field at the end of the assimilation interval was complete, and the cost function did not include a background term. Unless noted otherwise, the results described below are computed with the QIL. The 4D-Var minimization was performed using the LBFGS algorithm (Liu and Nocedal 1989), based on a limited-memory quasi-Newton method. It should be noted that the parameter for checking directional derivative condition (GTOL) in the LBFGS algorithm has to be chosen appropriately for each problem; after some experimentation, we chose it to be GTOL=0.1, which we found to be optimal for the 4D-Var in our case.
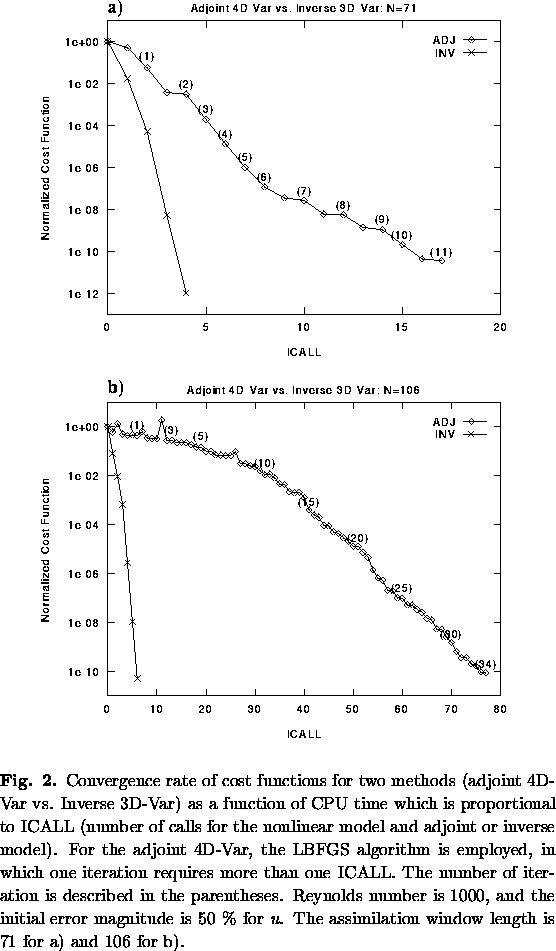
For an assimilation window of 71 time steps, the Inverse 3D-Var converged to less than 10-12 of its initial value in 4 iterations, whereas the adjoint algorithm required 11 iterations (and 17 computations of the gradient, each one involving a forward and backward integration) in order to converge to 10-10. For longer assimilation windows, the advantages of Inverse 3D-Var became more apparent. For example, when the assimilation window was extended to 106 time steps (Fig. 2b), Inverse 3D-Var converged to 10-10 in only 5 iterations. The 4D-Var, on the other hand, converged to the same value in 34 iterations, and almost 80 computations of the gradient (each one involving a forward and backward integration of the model or its adjoint). Choices of smaller GTOL resulted in a lack of convergence.
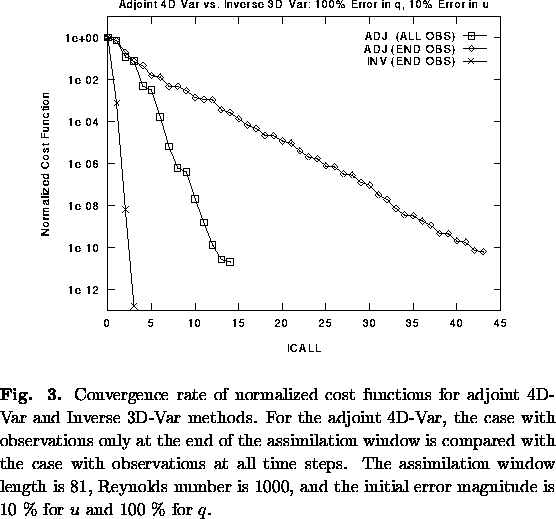
In Fig. 3 we have included passive transport of a scalar, with 10 % errors in the initial velocities u, and 100 % errors in q. For an assimilation window of 81 time steps, the Inverse 3D-Var converges to 10-13 of its original value after 3 iterations, but 4D-Var with data at the end of the interval requires 44 equivalent model integrations to converge to 10-10. If we provide 4D-Var with observations for every time step, it converges to 10-10 of the original cost function in 12 time integrations.
Many other experiments including observational and background errors were performed with uniformly good results. Some of the conclusions from these experiments (S. K. Park, personal communication, 1998) are:
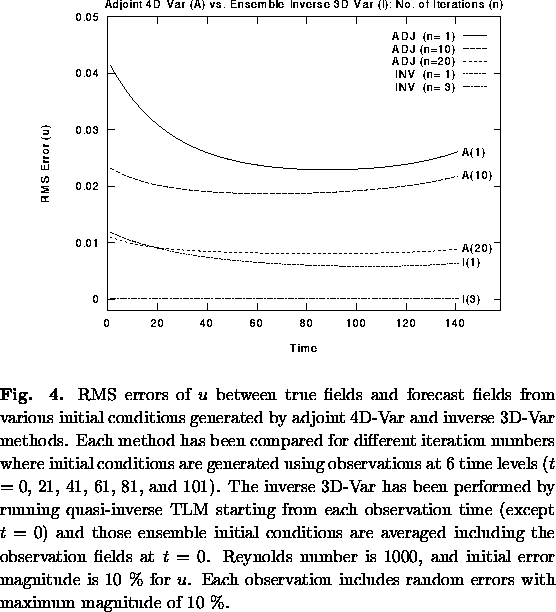
| Table 1. Variations in the cost function computed from different initial conditions generated by the same procedure as in Fig. 4 except that each 4D-Var (adjoint and ensemble inverse) has stopped at iteration numbers of 1 to 5. |
| Iteration | Adjoint | Ensemble Inverse |
| 0 | 41.8588 | 41.8588 |
| 1 | 22.5407 | 1.7420 |
| 2 | 2.1480 | 0.9197 |
| 3 | 2.0967 | 0.8881 |
| 4 | 0.8558 | 0.8787 |
| 5 | 0.8666 | 0.8746 |
c. Experiments with Lorenz 3 variable model
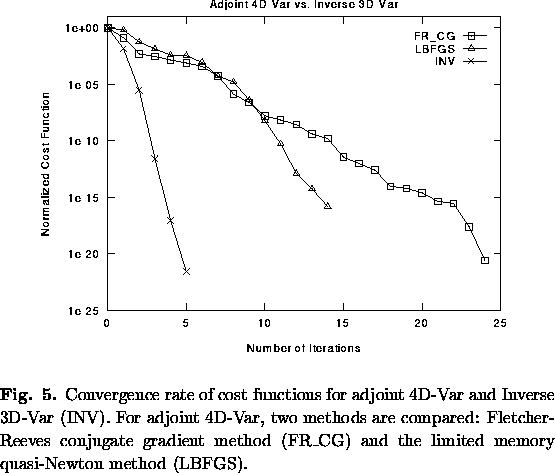
Inverse 3D-Var was also tested and compared with regular (adjoint) 4D-Var using Lorenz (1963) 3-variable model. Fig. 5 shows the evolution of the cost function using two different library minimization algorithms for the 4D-Var approach (limited-memory quasi-Newton or LBFGS, and Fletcher-Reeves conjugate gradient or FR_CG - see Navon and Legler (1987) for details) and the Inverse 3D-Var. The results are similar to those obtained with Burgers' equation: Inverse 3D-Var reduces the cost function to 10-10 in 3 iterations and to 10-22 in 6 iterations. The conjugate gradient and quasi-Newton methods converge to 10-14 in about 20 and 14 iterations respectively (where each iteration includes several forward nonlinear and backward adjoint integrations). Fig. 6 shows the cost function in the (X0,Y0) space and the descent approach of the 3 algorithms. The fact that Inverse 3D-Var is equivalent to a Newton algorithm is apparent by the directness of its convergence: both the descent direction and the amplitude of the step are optimal.
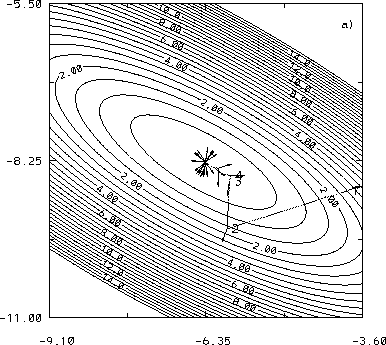
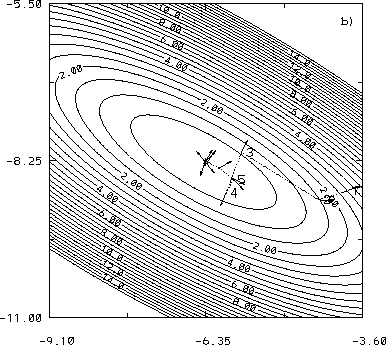

Several additional experiments with random errors in the initial
conditions, multiple levels of observations, and observations of
subset of variables and their combinations have also given
uniformly excellent results (J. Gao, personal communication,
1998).
5. Discussion
In the following discussion we first consider the relationship between the traditional 6-hour cycle for 3D-Var, 4D-Var, and Inverse 3D-Var (Cohn 1997; Courtier 1997). In 3D-Var (or previously in Optimal Interpolation) the observations were lumped together within a ![]() 3-hour window, and were assumed to have been taken at the center of the interval. For example, an analysis at 12Z included observations taken between 9Z and 15Z, but assumed to be observed at 12Z. For observations made, for example, at 10Z, this introduces two (relatively small) errors: the innovations (observations minus background) are computed with respect to a forecast at the wrong time, and the innovations are applied at the wrong time (12Z instead of 10Z). The first error can be easily corrected within 3D-Var: the background can be computed at the time of the observation, rather than at the center of the window. This correction is currently done at NCEP. However, only 4D-Var corrects the second error. 4D-Var (as implemented at ECMWF) computes the initial conditions valid at 9Z that best fit the data at their correct times throughout the 9Z-15Z interval. It minimizes a cost function that includes distance to the background at 9Z, plus the distance to the observations at their correct time (binned into one hour intervals). The 4D-Var ``analysis'' at 12Z is defined as the 3-hour forecast from the optimal initial conditions at 9Z. Because the minimization required about 80 iterations before reaching a satisfactory level, ECMWF has used a T63 model for the minimization, whereas the forecast model has T213 resolution.
3-hour window, and were assumed to have been taken at the center of the interval. For example, an analysis at 12Z included observations taken between 9Z and 15Z, but assumed to be observed at 12Z. For observations made, for example, at 10Z, this introduces two (relatively small) errors: the innovations (observations minus background) are computed with respect to a forecast at the wrong time, and the innovations are applied at the wrong time (12Z instead of 10Z). The first error can be easily corrected within 3D-Var: the background can be computed at the time of the observation, rather than at the center of the window. This correction is currently done at NCEP. However, only 4D-Var corrects the second error. 4D-Var (as implemented at ECMWF) computes the initial conditions valid at 9Z that best fit the data at their correct times throughout the 9Z-15Z interval. It minimizes a cost function that includes distance to the background at 9Z, plus the distance to the observations at their correct time (binned into one hour intervals). The 4D-Var ``analysis'' at 12Z is defined as the 3-hour forecast from the optimal initial conditions at 9Z. Because the minimization required about 80 iterations before reaching a satisfactory level, ECMWF has used a T63 model for the minimization, whereas the forecast model has T213 resolution.
Inverse 3D-Var offers some additional flexibility: If observations are complete, it allows transporting all the innovations from 9Z to 15Z to the desired time (12Z) essentially exactly (Fig. 1). The innovations at 12Z can then be analyzed into a 3D-Var that includes different background weights depending on the length of the forecast. In general, however, the observations are not complete, and a background error covariance needs to be introduced into the cost function. In that case, the Inverse 3D-Var analysis at the end of the assimilation interval is equivalent to 3D-Var, but the analysis is reached through a model integration, which can be advantageous in reducing problems of spin up. When knowledge of ``future'' observations is available (as in reanalysis), and the goal is to optimize the analysis (rather than to improve the forecast), the Inverse 3D-Var can also be used, as suggested by the forecast sensitivity applications.
We have seen that Inverse 3D-Var has several potential advantages, including accuracy, efficiency and flexibility, and these have been apparent in the simple model experiments. It also has some potentially serious disadvantages, but we believe they can be overcome with further development and experimentation:
We are currently planning to test the Inverse 3D-Var approach on the ARPS model, by combining it with a 3D-Var analysis including Doppler radar observations of radial velocities and reflectivities, using a linear tangent model with simplified reversible physics. If successful, we will also attempt to apply this method to the NCEP global model, where it could be applied, for example, in the second phase of the global Reanalysis project (Kalnay et al. 1996), where ``future'' data is available during the assimilation.
Acknowledgments. This work was started at NCEP's Environmental Modeling Center. We would like to express our special gratitude to David Zhi Wang and his co-authors, for introducing similar ideas on the acceleration of 4D-Var, and Jerry Straka for developing a reversible parameterization of convection. Discussions with Kelvin Droegemeier, Keith Brewster, Alan Shapiro and Brian Fiedler at the University of Oklahoma, Mark Iredell, Wan-Shu Wu, Zoltan Toth, M. Zupanski, D. Zupanski at NCEP, R. Menard and S. Cohn at NASA/DAO, Carolyn Reynolds, Tim Palmer, and Michael Navon were also helpful. We are especially grateful to Olivier Talagrand, Andrew Lorenc, Francois Bouttier, Istvan Szunyogh, Jim Purser, John Derber and David Parrish for their insightful comments on an early version of the paper.
The support and encouragement of Peter Lamb (CIMMS), Kelvin
Droegemeier (CAPS), and Fred Carr (School of Meteorology), and Ron
McPherson and Stephen Lord (NCEP) are gratefully acknowledged.
This research was supported by DOC/NOAA under Grant NA67J0160
through CIMMS and NSF under Grant ATM91-20009 through CAPS.
7. References